AlphaOne
Reasoning Models Thinking Slow and Fast at Test Time
Junyu Zhang
 †
Runpei Dong
†
Han Wang
Xuying Ning
†
Runpei Dong
†
Han Wang
Xuying Ning
Haoran Geng Peihao Li
Xialin He
Yutong Bai
Jitendra Malik
Peihao Li
Xialin He
Yutong Bai
Jitendra Malik
Saurabh Gupta
Huan Zhang
†
Runpei Dong
†
Han Wang
Xuying Ning
Haoran Geng
Yutong Bai
Saurabh Gupta
Huan Zhang
University of Illinois Urbana-Champaign
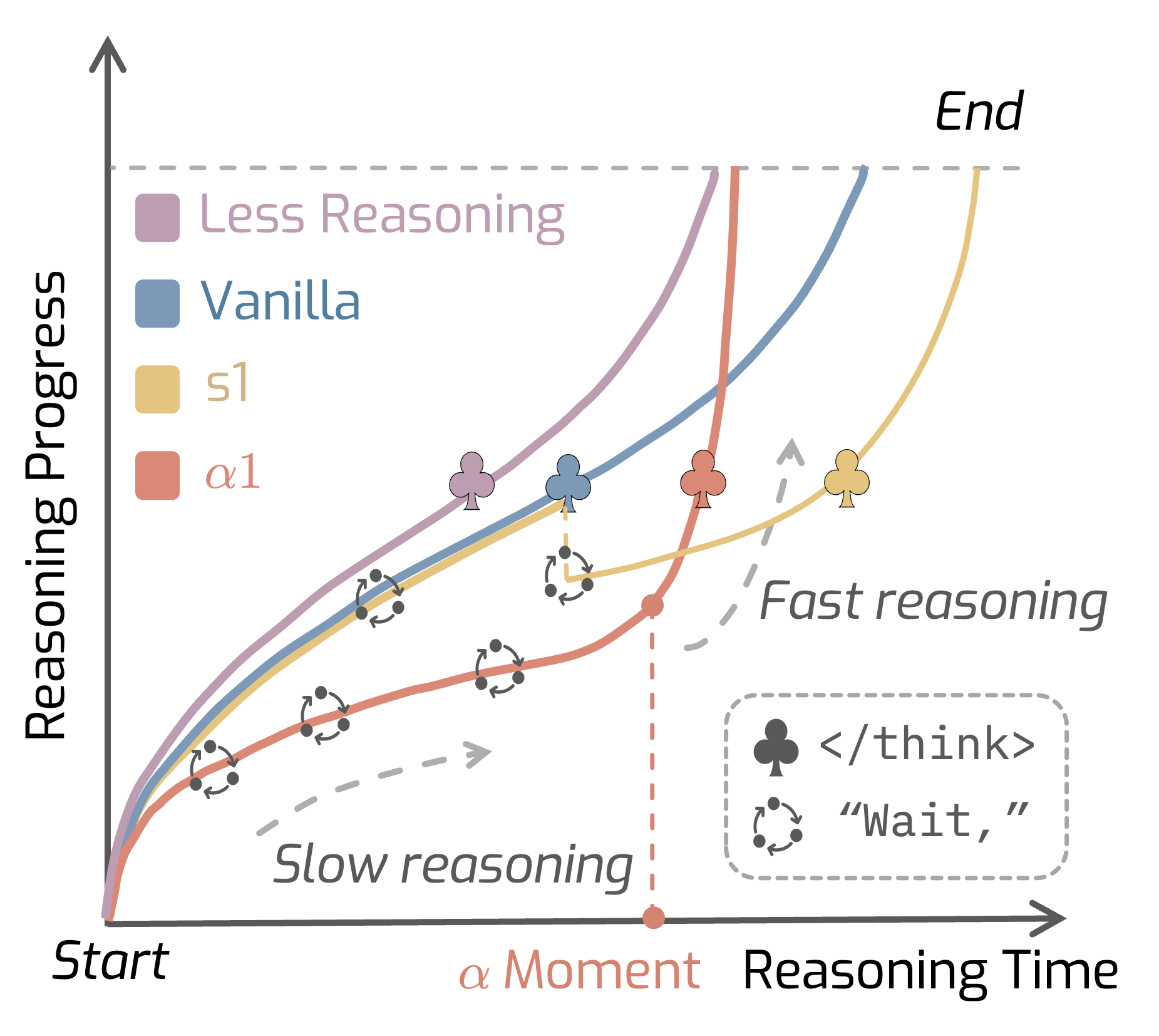

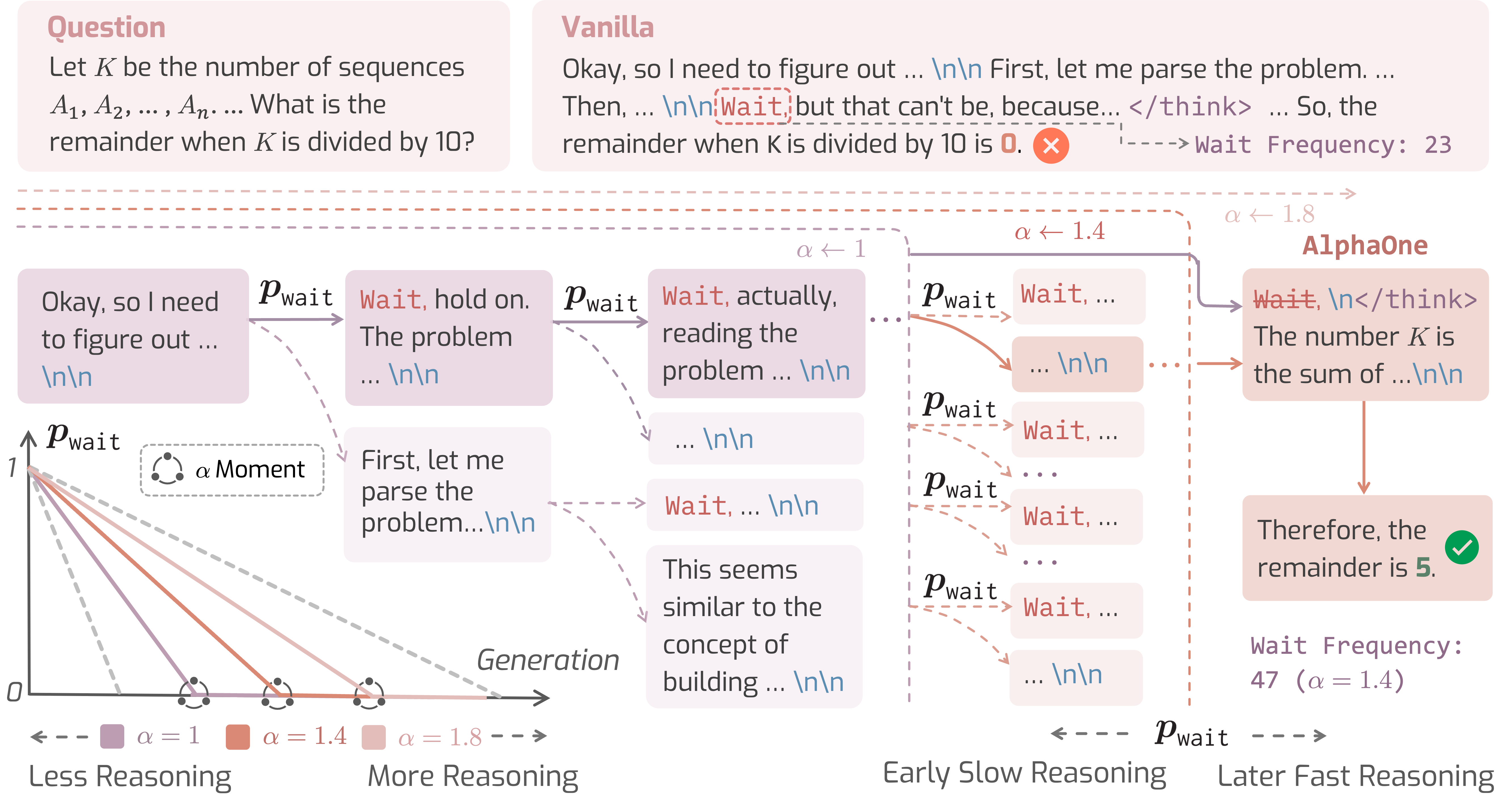
 ). Here
). Here  represents
represents  moment.
moment.